---
tags:
- kernel
license: apache-2.0
---
# Activation
Activation is a python package that contains custom CUDA-based activation kernels, primarily targeting AMD GPUs.
- Currently implemented
- [PolyNorm](https://arxiv.org/html/2411.03884v1)
- [RMSNorm](https://docs.pytorch.org/docs/stable/generated/torch.nn.RMSNorm.html)
- **FusedAddRMSNorm**
A fused operator that combines **residual addition** (`x + residual`) with **RMSNorm** in a single kernel.
- Instead of:
```python
y = x + residual
hidden_state = rms_norm(y, weight, eps)
out = y + some_op(hidden_state)
```
- Fused as:
```python
hidden_state, y = fused_add_rms_norm(x, residual, weight, eps)
out = y + some_op(hidden_state)
```
- **FusedMulPolyNorm**
A fused operator that combines **PolyNorm** with an **element-wise multiplication** by a Tensor.
- Instead of:
```python
y = poly_norm(x, weight, bias, eps)
out = y * a
```
- Fused as:
```python
out = fused_mul_poly_norm(x, a, weight, bias, eps)
```
## Usage
```python
import torch
from kernels import get_kernel
activation = get_kernel("motif-technologies/activation")
torch.set_default_device("cuda")
poly_norm = activation.layers.PolyNorm(eps=1e-6)
x = torch.randn(10, 10)
print(poly_norm(x))
```
## Performance
- Test cases are from the Motif LLM
- The results can be reproduced using the provided benchmarking tools.
- For details on how to use the benchmarking tools, please refer to the [benchmarks README](./benchmarks/README.md).
- The benchmark results may show fluctuations, especially in the backward pass and when the dimension size is small.
### RMSNorm
#### H100 Results
Forward Performance

Backward Performance

#### MI250 Results
Forward Performance

Backward Performance

---
### FusedAddRMSNorm
> [!NOTE]
> For fusion case performance, the **non-fused baseline** was implemented with our **custom kernels**.
#### H100 Results
Forward Performance

Backward Performance

#### MI250 Results
Forward Performance

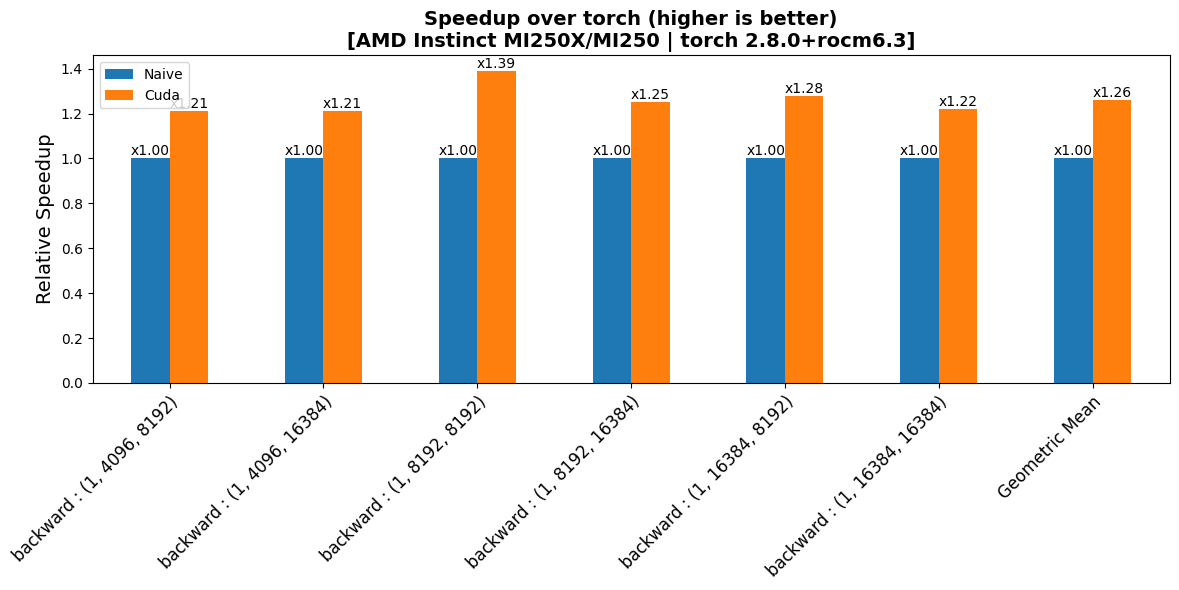
Backward Performance

---
### PolyNorm
#### H100 Results
Forward Performance

Backward Performance

#### MI250 Results
Forward Performance

Backward Performance

---
### FusedMulPolyNorm
> [!NOTE]
> For fusion case performance, the **non-fused baseline** was implemented with our **custom kernels**.
#### H100 Results
Forward Performance

Backward Performance

#### MI250 Results
Forward Performance

Backward Performance
## Pre-commit Hooks
This project uses [pre-commit](https://pre-commit.com/) to automatically check and format code before commits.
### Setup
1. Install pre-commit:
```bash
pip install pre-commit
```
2. Install the git hooks:
```bash
pre-commit install
```
Once installed, the configured hooks will run automatically on each commit.
### Included Hooks
The following tools are run via pre-commit:
- **[yapf](https://github.com/google/yapf)** – Python code formatter
- **[typos](https://github.com/crate-ci/typos)** – Spell checker for common typos
- **[isort](https://github.com/PyCQA/isort)** – Organizes and sorts Python imports
- **[clang-format](https://clang.llvm.org/docs/ClangFormat.html)** – Formats C++/CUDA code (`--style=file`)
- **[pymarkdown](https://github.com/jackdewinter/pymarkdown)** – Lints and auto-fixes Markdown files
- **[actionlint](https://github.com/rhysd/actionlint)** – Validates GitHub Actions workflows
### Usage
- Run all checks on the entire codebase:
```bash
pre-commit run --all-files
```
- Run a specific hook (example: isort):
```bash
pre-commit run isort --all-files
```