[](./LICENSE)
[](https://github.com/InternLM/xtuner/)
[](https://github.com/InternLM/lmdeploy/)
[](https://github.com/sgl-project/sglang/)
[](https://github.com/vllm-project/vllm/)
[💻 Github](https://github.com/InternLM/POLAR) |
[📜 Paper](https://arxiv.org/abs/xxxxxx)
[English](./README.md) |
[简体中文](./README_zh-CN.md)
# Introduction
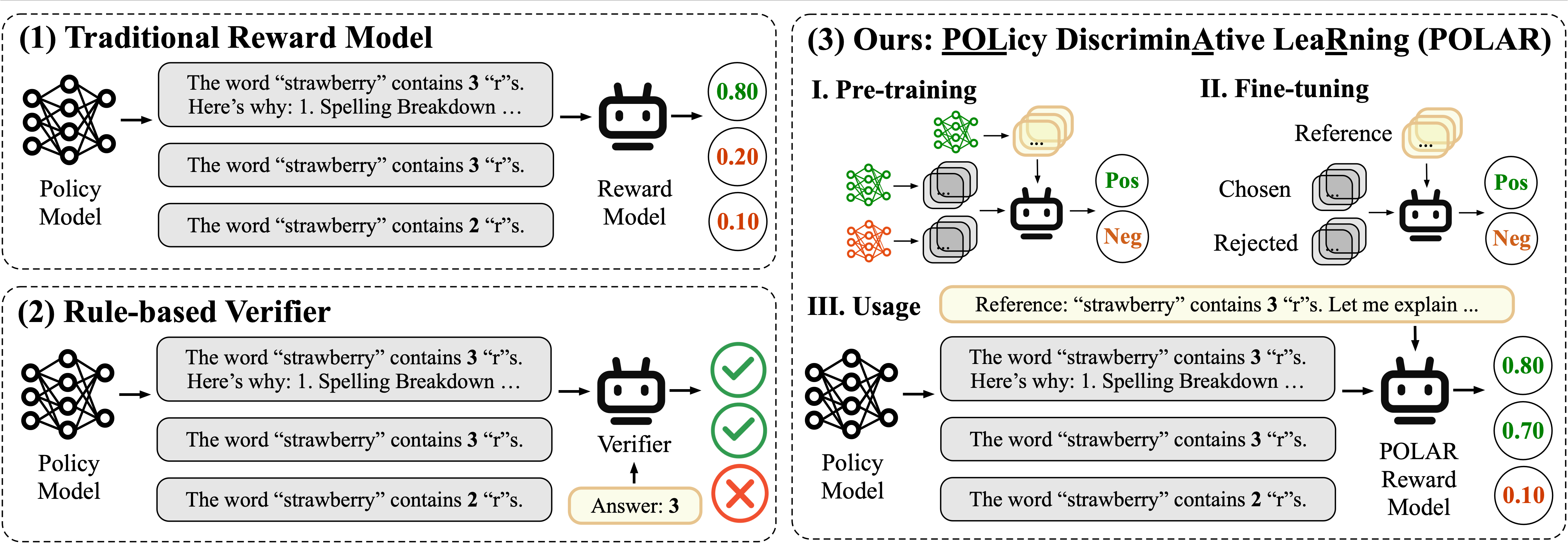
POLAR represents a significant breakthrough in scalar-based reward models achieved through large-scale pre-training. It leverages the innovative **POL**icy Discrimin**A**tive Lea**R**ning (**POLAR**) paradigm——a scalable, high-level optimization objective——to effectively discriminate between policies using a large-scale synthetic corpora. Following pre-training, POLAR RMs are fine-tuned with minimal preference data, rapidly aligning with human preferences. Key features of POLAR include:
* **Innovative Pre-training Paradigm:** POLAR trains a reward model to discern identical policies and discriminate different ones. Unlike traditional reward modeling methods relying on absolute preferences, POLAR captures the relative difference between two policies, which is a scalable, high-level optimization objective suitable for modeling generic ranking relationships.
* **Tailored for Reinforcement Fine-tuning:** POLAR assigns rewards to LLM trajectories based on given references, perfectly aligning with the Reinforcement Fine-tuning (RFT) framework. POLAR provides a promising solution for applying RFT in generic scenarios.
* **Superior Performance and Generalization:** POLAR achieves state-of-the-art results on downstream reinforcement learning tasks, consistently delivering accurate and reliable reward signals that generalize effectively to unseen scenarios and significantly reducing reward hacking.
* **Easy to Customize:** Pre-trained checkpoints of POLAR are available, enabling researchers to conveniently fine-tune the RM for various customized scenarios, thus facilitating straightforward adaptation and expansion tailored to specific applications and experimental requirements.