
zRzRzRzRzRzRzR
commited on
Commit
·
b871d19
1
Parent(s):
07a3fb5
README.md
CHANGED
|
@@ -1,3 +1,51 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- zh
|
| 6 |
+
base_model:
|
| 7 |
+
- THUDM/GLM-4-9B-0414
|
| 8 |
+
pipeline_tag: image-text-to-text
|
| 9 |
+
library_name: transformers
|
| 10 |
+
tags:
|
| 11 |
+
- reasoning
|
| 12 |
---
|
| 13 |
+
|
| 14 |
+
# GLM-4.1V-9B-Base
|
| 15 |
+
|
| 16 |
+
## Model Introduction
|
| 17 |
+
|
| 18 |
+
Vision-Language Models (VLMs) have become foundational components of intelligent systems. As real-world AI tasks grow
|
| 19 |
+
increasingly complex, VLMs must evolve beyond basic multimodal perception to enhance their reasoning capabilities in
|
| 20 |
+
complex tasks. This involves improving accuracy, comprehensiveness, and intelligence, enabling applications such as
|
| 21 |
+
complex problem solving, long-context understanding, and multimodal agents.
|
| 22 |
+
|
| 23 |
+
Based on the [GLM-4-9B-0414](https://github.com/THUDM/GLM-4) foundation model, we present the new open-source VLM model
|
| 24 |
+
**GLM-4.1V-9B-Thinking**, designed to explore the upper limits of reasoning in vision-language models. By introducing
|
| 25 |
+
a "thinking paradigm" and leveraging reinforcement learning, the model significantly enhances its capabilities. It
|
| 26 |
+
achieves state-of-the-art performance among 10B-parameter VLMs, matching or even surpassing the 72B-parameter
|
| 27 |
+
Qwen-2.5-VL-72B on 18 benchmark tasks. We are also open-sourcing the base model GLM-4.1V-9B-Base to
|
| 28 |
+
support further research into the boundaries of VLM capabilities.
|
| 29 |
+
|
| 30 |
+
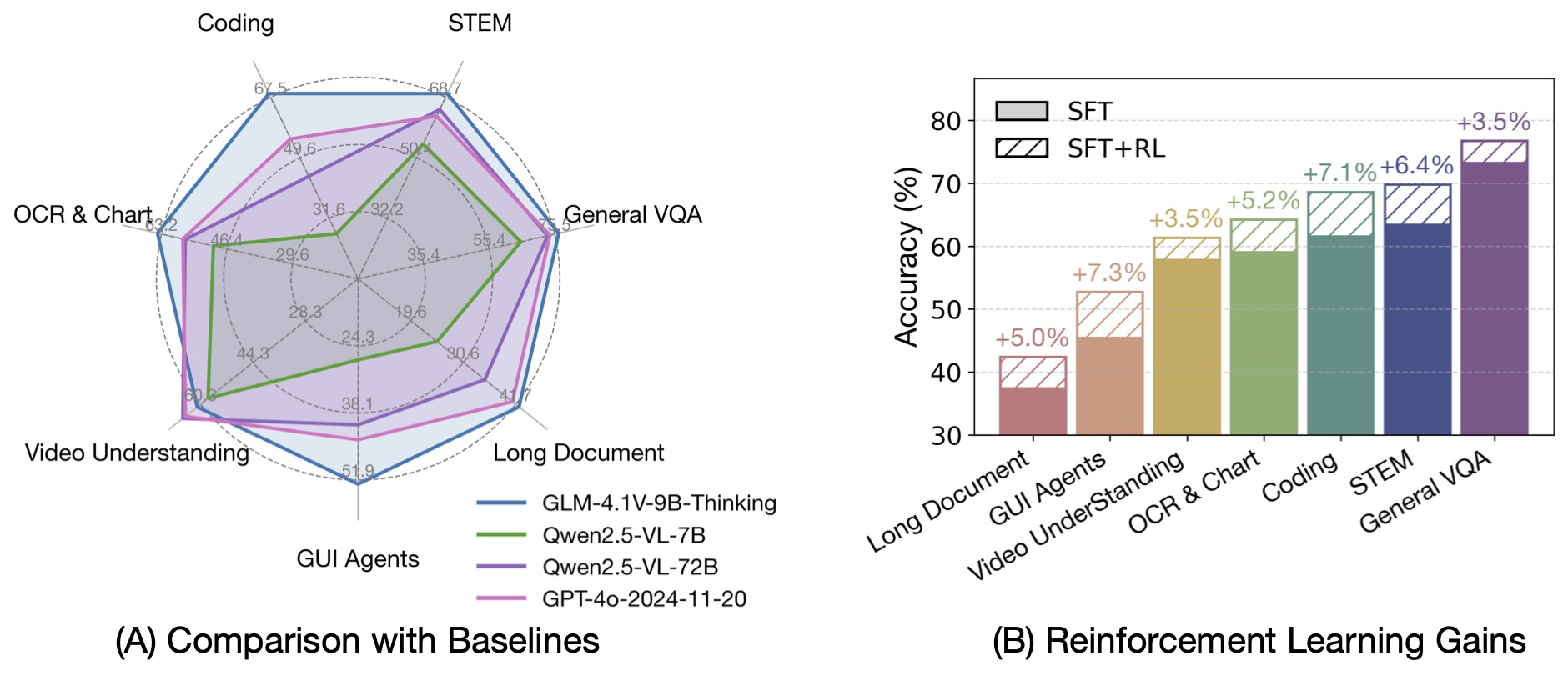
|
| 31 |
+
|
| 32 |
+
Compared to the previous generation models CogVLM2 and the GLM-4V series, **GLM-4.1V-Thinking** offers the
|
| 33 |
+
following improvements:
|
| 34 |
+
|
| 35 |
+
1. The first reasoning-focused model in the series, achieving world-leading performance not only in mathematics but also
|
| 36 |
+
across various sub-domains.
|
| 37 |
+
2. Supports **64k** context length.
|
| 38 |
+
3. Handles **arbitrary aspect ratios** and up to **4K** image resolution.
|
| 39 |
+
4. Provides an open-source version supporting both **Chinese and English bilingual** usage.
|
| 40 |
+
|
| 41 |
+
## Benchmark Performance
|
| 42 |
+
|
| 43 |
+
By incorporating the Chain-of-Thought reasoning paradigm, GLM-4.1V-9B-Thinking significantly improves answer accuracy,
|
| 44 |
+
richness, and interpretability. It comprehensively surpasses traditional non-reasoning visual models.
|
| 45 |
+
Out of 28 benchmark tasks, it achieved the best performance among 10B-level models on 23 tasks,
|
| 46 |
+
and even outperformed the 72B-parameter Qwen-2.5-VL-72B on 18 tasks.
|
| 47 |
+
|
| 48 |
+

|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
For video reasoning, web demo deployment, and more code, please check our [GitHub](https://github.com/THUDM/GLM-4.1V-Thinking).
|