|
|
--- |
|
|
license: apache-2.0 |
|
|
language: |
|
|
- en |
|
|
base_model: |
|
|
- Qwen/Qwen-Image |
|
|
pipeline_tag: text-to-image |
|
|
library_name: diffusers |
|
|
widget: |
|
|
- text: >- |
|
|
cute anime girl with massive fennec ears and a big fluffy fox tail with long |
|
|
wavy blonde hair between eyes and large blue eyes blonde colored eyelashes |
|
|
chubby wearing oversized clothes summer uniform long blue maxi skirt muddy |
|
|
clothes happy sitting on the side of the road in a run down dark gritty |
|
|
cyberpunk city with neon and a crumbling skyscraper in the rain at night |
|
|
while dipping her feet in a river of water she is holding a sign that says |
|
|
"ComfyUI is the best" written in cursive |
|
|
output: |
|
|
url: workflow-demo1.png |
|
|
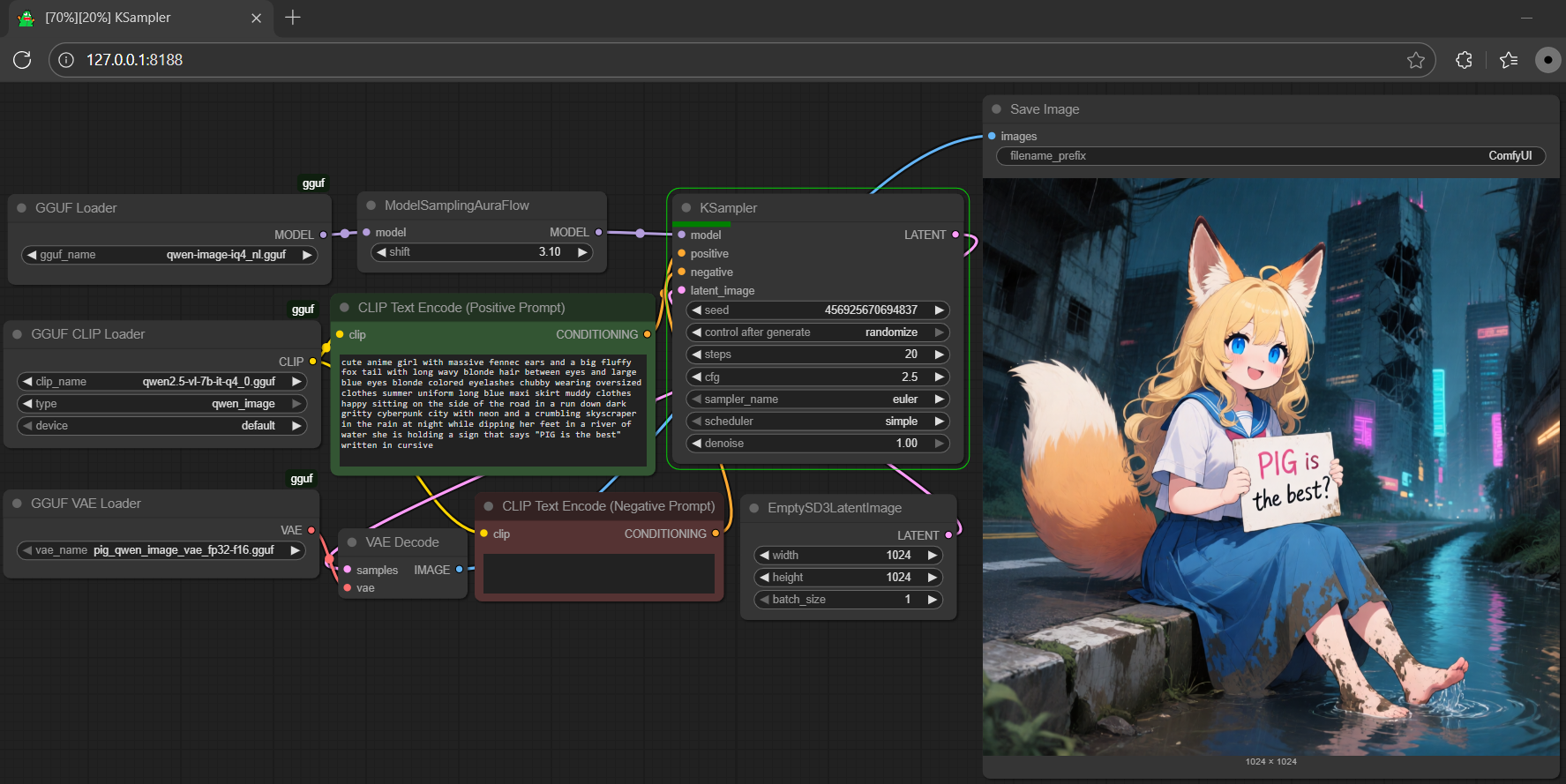
- text: >- |
|
|
cute anime girl with massive fennec ears and a big fluffy fox tail with long |
|
|
wavy blonde hair between eyes and large blue eyes blonde colored eyelashes |
|
|
chubby wearing oversized clothes summer uniform long blue maxi skirt muddy |
|
|
clothes happy sitting on the side of the road in a run down dark gritty |
|
|
cyberpunk city with neon and a crumbling skyscraper in the rain at night |
|
|
while dipping her feet in a river of water she is holding a sign that says |
|
|
"PIG is the best" written in cursive |
|
|
output: |
|
|
url: workflow-demo2.png |
|
|
- text: >- |
|
|
cute anime girl with massive fennec ears and a big fluffy fox tail with long |
|
|
wavy blonde hair between eyes and large blue eyes blonde colored eyelashes |
|
|
chubby wearing oversized clothes summer uniform long blue maxi skirt muddy |
|
|
clothes happy sitting on the side of the road in a run down dark gritty |
|
|
cyberpunk city with neon and a crumbling skyscraper in the rain at night |
|
|
while dipping her feet in a river of water she is holding a sign that says |
|
|
"1+1=2 is it correct?" written in cursive |
|
|
output: |
|
|
url: workflow-demo3.png |
|
|
tags: |
|
|
- gguf-node |
|
|
- gguf-connector |
|
|
--- |
|
|
# **gguf quantized version of qwen-image** |
|
|
- run it straight with `gguf-connector` |
|
|
``` |
|
|
ggc q5 |
|
|
``` |
|
|
> |
|
|
>GGUF file(s) available. Select which one to use: |
|
|
> |
|
|
>1. qwen-image-iq2_s.gguf |
|
|
>2. qwen-image-iq4_nl.gguf |
|
|
>3. qwen-image-q4_0.gguf |
|
|
>4. qwen-image-q8_0.gguf |
|
|
> |
|
|
>Enter your choice (1 to 4): _ |
|
|
> |
|
|
## **run it with gguf-node via comfyui** |
|
|
- drag **qwen-image** to > `./ComfyUI/models/diffusion_models` |
|
|
- drag **qwen2.5-vl-7b** [[4.43GB](https://huggingface.co/chatpig/qwen2.5-vl-7b-it-gguf/blob/main/qwen2.5-vl-7b-it-q4_0.gguf)] to > `./ComfyUI/models/text_encoders` |
|
|
- drag **pig** [[254MB](https://huggingface.co/calcuis/pig-vae/blob/main/pig_qwen_image_vae_fp32-f16.gguf)] to > `./ComfyUI/models/vae` |
|
|
|
|
|
<Gallery /> |
|
|
|
|
|
 |
|
|
|
|
|
tip: the text encoder used for this model is qwen2.5-vl-**7b**; get more encoder either [here](https://huggingface.co/calcuis/pig-encoder/tree/main) (pig quant) or [here](https://huggingface.co/chatpig/qwen2.5-vl-7b-it-gguf/tree/main) (llama.cpp quant); the size is different from the one (qwen2.5-vl-**3b**) used in **omnigen2** |
|
|
|
|
|
## **run it with diffusers** |
|
|
```py |
|
|
import torch |
|
|
from diffusers import DiffusionPipeline, GGUFQuantizationConfig, QwenImageTransformer2DModel |
|
|
|
|
|
model_path = "https://huggingface.co/calcuis/qwen-image-gguf/blob/main/qwen-image-q2_k.gguf" |
|
|
transformer = QwenImageTransformer2DModel.from_single_file( |
|
|
model_path, |
|
|
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16), |
|
|
torch_dtype=torch.bfloat16, |
|
|
config="callgg/qi-decoder", |
|
|
subfolder="transformer" |
|
|
) |
|
|
pipe = DiffusionPipeline.from_pretrained( |
|
|
"callgg/qi-decoder", |
|
|
transformer=transformer, |
|
|
torch_dtype=torch.bfloat16, |
|
|
) |
|
|
pipe.enable_model_cpu_offload() |
|
|
|
|
|
prompt = "a pig holding a sign that says hello world" |
|
|
positive_magic = {"en": "Ultra HD, 4K, cinematic composition."} |
|
|
negative_prompt = " " |
|
|
image = pipe( |
|
|
prompt=prompt + positive_magic["en"], |
|
|
negative_prompt=negative_prompt, |
|
|
height=1024, |
|
|
width=1024, |
|
|
num_inference_steps=24, |
|
|
true_cfg_scale=2.5, |
|
|
generator=torch.Generator() |
|
|
).images[0] |
|
|
image.save("output.png") |
|
|
``` |
|
|
|
|
|
note: diffusers not yet supported t and i quants; opt gguf-node via comfyui or run it straight with gguf-connector |
|
|
|
|
|
### **reference** |
|
|
- base model from [qwen](https://huggingface.co/Qwen) |
|
|
- distilled model from [modelscope](https://github.com/modelscope/DiffSynth-Studio) |
|
|
- lite model is a lora merge from [lightx2v](https://huggingface.co/lightx2v/Qwen-Image-Lightning) |
|
|
- comfyui from [comfyanonymous](https://github.com/comfyanonymous/ComfyUI) |
|
|
- diffusers from [huggingface](https://github.com/huggingface/diffusers) |
|
|
- gguf-node ([pypi](https://pypi.org/project/gguf-node)|[repo](https://github.com/calcuis/gguf)|[pack](https://github.com/calcuis/gguf/releases)) |
|
|
- gguf-connector ([pypi](https://pypi.org/project/gguf-connector)) |
