
license: apache-2.0
language:
- en
base_model:
- Qwen/Qwen3-4B
pipeline_tag: visual-question-answering
R-4B
[📚 Arxiv Paper (Coming soon))] [🤗 Hugging Face] [🤖️ ModelScope] [💻 Code]
⭐️ Introduction
In this report, we present R-4B, a multimodal large language model designed to achieve adaptive multimodal reasoning—dynamically choosing between step-by-step thinking and direct response generation based on task complexity. This capability enables R-4B to deliver high-quality responses while significantly improving inference efficiency and reducing computational costs.
The development of R-4B follows a two-stage training paradigm: (1) Dual-Capability Pretraining, which establishes both thinking and non-thinking capabilities for VQA; and (2) Adaptive Thinking Post-Training, which enables the model to adaptively switch between modes based on input demands.
R-4B achieves state-of-the-art performance among models of its scale. In evaluations across multiple public benchmarks, R-4B outperforms Qwen2.5-VL-7B on nearly all tasks. Notably, it matches or exceeds the performance of the much larger Kimi-VL-Thinking-2506 (3B activated, 16B total parameters).
🔥 Quickstart
Below, we provide simple examples to show how to use R-4B with 🤗 Transformers.
Using 🤗 Transformers to Chat
Following Qwen3, we also offer a hard switch mechanism that lets users dynamically control the model's behavior.
import requests
import torch
from transformers import AutoModel, AutoProcessor
model_path = "YannQi/R-4B"
from PIL import Image
model = AutoModel.from_pretrained(
model_path,
torch_dtype=torch.float16,
trust_remote_code=True,
).to('cuda')
# default processer
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": f"{image_file}",
},
{"type": "text", "text": "描述该图片。"},
],
}
]
# Preparation for inference
text_auto_thinking = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True) # thinking_mode='long' for thinking mode; thinking_mode='short' for non-thinking mode; Defalut is auto-thinking mode.
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs_auto_thinking = processor(images=raw_image, text=text_auto_thinking, return_tensors='pt').to(0, torch.float16)
inputs_auto_thinking = inputs_auto_thinking.to("cuda")
# Inference: Generation of the output
generated_ids_auto_thinking = model.generate(**inputs_auto_thinking, max_new_tokens=8192)
generated_ids_trimmed_auto_thinking = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs_auto_thinking.input_ids, generated_ids_auto_thinking)
]
output_text_auto_thinking = processor.batch_decode(
generated_ids_trimmed_auto_thinking, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print("Auto Thinking Output:", output_text_auto_thinking)
📈 Experimental Results
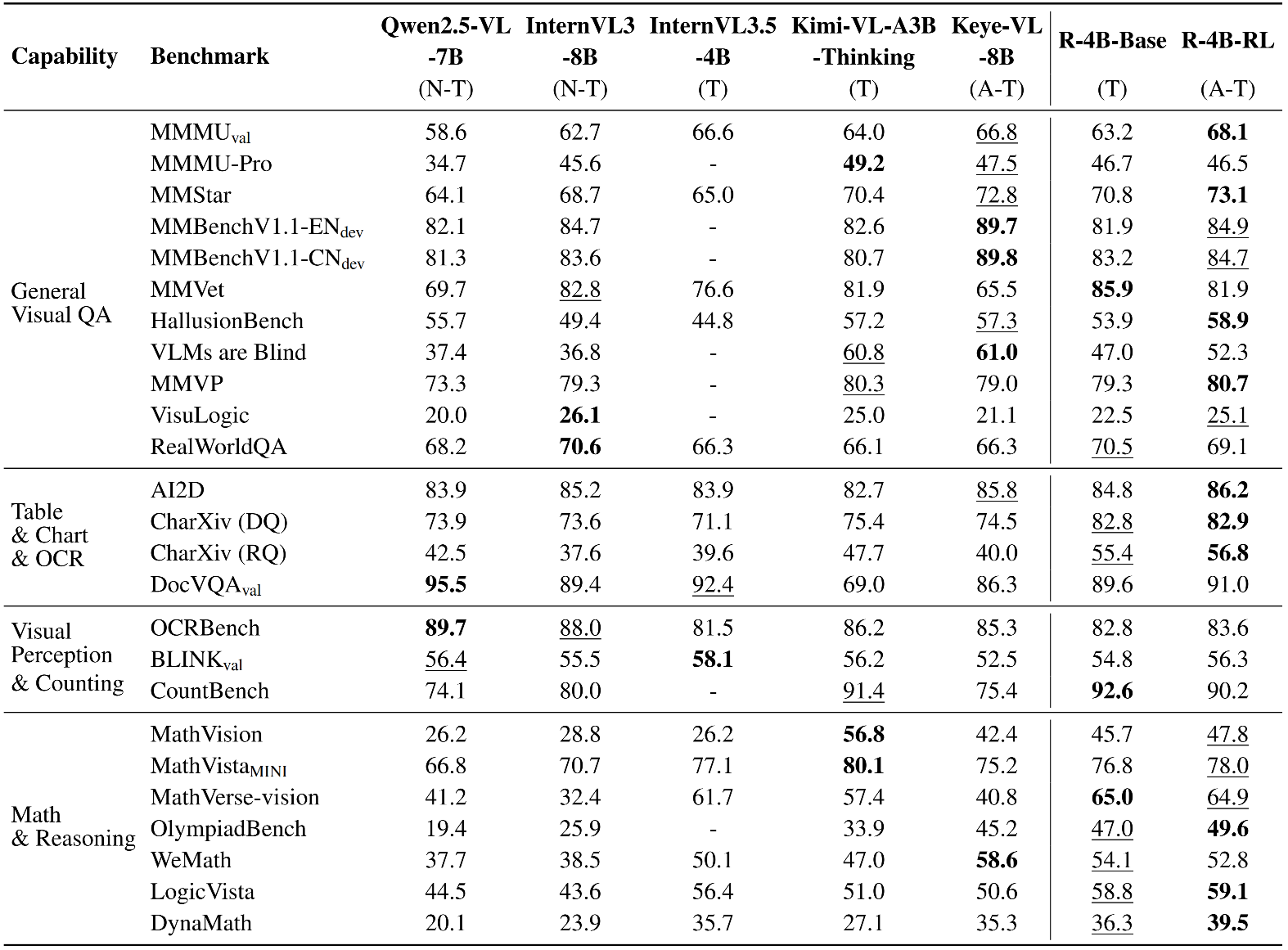
- R-4B establishes itself with powerful, state-of-the-art perceptual abilities that are competitive with larger models.
- In evaluation sets that require complex logical reasoning and mathematical problem-solving, such as WeMath, MathVerse, and LogicVista, R-4B displays a strong performance curve. This highlights its advanced adaptive thinking capacity for logical deduction and solving complex quantitative problems.
✒️ Citation
Coming soon!
Acknowledgement
R-4B is developed based on the codebases of the following projects: LLaVA-Next, SigLIP, Qwen3, Qwen2.5-VL, VLMEvalKit. We sincerely thank these projects for their outstanding work.